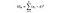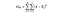분산 분석(일반적으로 분산 분석)은 입문 통계 클래스에서 종종 호도됩니다. 오늘날의 기술을 사용하면 컴퓨터가 모든 계산을 수행하고 위와 같은 바쁜 표의 끝 부분에있는 값을 쉽게 볼 수 있습니다. 이 글에서,나는이 숫자가 무엇을 통해 갈거야 어떤 분산 분석은 실제로 무엇을하고 있습니다.
분산 분석의 주요 아이디어는 샘플의 하위 그룹 사이에 측정 된 평균에 통계적으로 유의 한 차이가 있는지 테스트하는 것입니다. 이 개념은 작물 수확량에 대한 방대한 양의 데이터를 분석 한 로널드 피셔라는 영국의 통계 학자와 함께 1920 년경으로 거슬러 올라갑니다. 피셔 분산 분석을 사용하여 감자의 평균 무게에 상당한 차이가 있었을 때 다른 비료를 사용했습니다.
현재 분산 분석을 시연하기 위해 나는 감자의 무게보다는 와인의 가격을 살펴볼 것이다. 이 예제에 대한 데이터는 와인 열정의 와인 병에 대한 수천 개의 리뷰가 포함 된 카글의 와인 검토 데이터 세트입니다. 나는 미국,이탈리아,프랑스(국가 당 1,000)에서 와인에 대한 3,000 리뷰의 하위 집합으로 필터링 한 원산지 국가 간의 평균 가격에 통계적으로 유의 한 차이가 있는지 테스트하기 위해 분산 분석을 사용합니다.
국가 별 가격 분포의 빠른 플롯은 세 가지 매우 유사한 분포를 보여 주며 대부분의 가격은 한 병에 약 25 달러입니다.
저자
각 나라의 평균을 보면,프랑스는 평균적으로 가장 비싼 와인을 가지고 있으며,이탈리아와 마침내 미국이 그 뒤를 따릅니다. 그러나 문제는 이것이 국가 간 가격의 진정한 차이입니까,아니면 샘플 변형으로 인한 것일 수 있습니까? 분산 분석 놀이로 오는 곳이다.
wine_df.groupby('country').mean()country France 37.242 Italy 35.286 US 33.776 Name: price, dtype: float64
분산 분석의 네 단계는 다음과 같습니다:
1. 가설을 공식화 2. 유의 수준 설정 3. 통계량 4 를 계산하십시오. 이 경우 통계량 값을 계산할 수 있습니다. 가설을 공식화
거의 모든 통계적 유의성 검정과 마찬가지로,분산 분석은 귀무 및 대립 가설을 공식화하는 것으로 시작합니다. 이 예에서 가설은 다음과 같습니다:
귀무 가설: 세 나라 사이의 와인의 평균 가격에 차이가 없다;그들은 모두 동일합니다. 대립 가설:와인의 평균 가격은 세 나라 사이에 동일하지 않다.
참고,이것은 옴니버스 테스트,우리가 귀무 가설을 거부 할 수 있다면 그것은 통계적으로 유의 한 차이가 이들 국가 사이에 어딘가에 존재한다는 것을 우리에게 말할 것이다 의미,하지만 그것이 어디 그것은 우리에게 말하지 않을 것이다.
유의 수준 설정
유의 수준 또는 알파는 귀무 가설이 실제로 사실 일 때 거부 할 확률입니다. 다른 용어로,그것은 제 1 형 오류를 만들 확률입니다.
일반적으로 실험에 가장 적합한 알파를 결정하기 위해 유형 1 과 유형 2 오류를 만드는 비용을 측정해야하지만,이 장난감 예제에서는 표준을 사용하겠습니다.05 우리의 05 값입니다.
계산 에프-통계
에프-통계는 단순히 샘플 평균 내의 분산 대 샘플 평균 간의 분산의 비율입니다. 이 분산 분석 테스트를 위해 각 국가의 평균 와인 가격이 전체 평균 가격에서 얼마나 멀리 떨어져 있는지 살펴보고 각 국가의 샘플 분포 내에서 얼마나 많은 가격 변동으로 나눕니다. 우리가 그것을 부서버릴 까지 복잡하게 본 일지모른는,에프 통계 공식은 아래와 같는다.
이미지 작성자
그룹 간의 제곱합. 이것은 각 그룹의 평균과 전체 평균 시간 그룹 당 요소 수 간의 제곱 차이의 합계입니다. 이 예에서는 각 국가의 와인 가격의 평균을 취하고 전체 평균에서 뺀 다음 차이를 제곱하고 1,000(국가 당 데이터 포인트 수)을 곱합니다.
작성자 별 이미지
그룹 내의 제곱합. 이것은 그룹 평균과 그룹의 각 값 간의 제곱 차이의 합계입니다. 프랑스의 경우 프랑스 와인의 평균 가격을 취한 다음 해당 그룹의 천 개 데이터 포인트의 프랑스 와인 각 병에 대한 차이를 빼고 제곱합니다.
저자 이미지
그룹 간의 자유도,단순히 그룹 수를 뺀 1 입니다. 우리는 우리가 비교하는 세 개의 다른 국가가,그래서 여기에 자유의 정도는 2 입니다. 자유도=그룹 내의 자유도,단순히 데이터 포인트 수에서 그룹 수를 뺀 값입니다. 우리는 3,000 개의 데이터 포인트와 3 개의 다른 국가를 가지고 있습니다.
그룹에 대한 제곱의 합을 자유도로 나누면 해당 그룹에 대한 평균 제곱이 산출되며,에프 통계는 내 평균 제곱에 대한 평균 제곱의 비율입니다.
아래에서는 파이썬에서 이러한 값을 수동으로 계산하고~4.07 의 통계로 끝납니다.
Sum of Squares Between: 6039.73 Sum of Squares Within: 2226089.55 Degrees of Freedom for SSB: 2 Degrees of Freedom for SSW: 2997 F-Statistic: 4.06567
사용 에프-통계,계산 피-값
일단 우리가 우리의 에프-통계,우리는 에프-분포에 연결 피-값을 얻을 수 있습니다. 당신은 어떤 통계 책의 뒷면에이 값에 대한 테이블을 찾을 수 있습니다 또는 당신을 위해이 작업을 수행 할 것입니다 훨씬 쉽게 온라인 계산기가있다. 우리의 특정 자유도로,에프-통계 4.07 은 피-값을 산출합니다.0172.
귀무가설을 거부할지 여부를 결정하기 위해 피-가치와 유의 수준을 비교
우리의 피-값은 귀무 가설(모든 국가가 동일한 평균 와인 가격을 가짐)이 사실이라고 가정하면 대략 1 이 있음을 의미합니다.우리는 깎아 지른듯한 샘플링 기회로 가지고있는 데이터를 보는 7%의 기회. 이 모든 것보다 먼저 유의 수준 또는 알파를 5%로 설정함으로써,우리는 그것이 사실 일 때 널을 거부 할 확률이 5%를 기꺼이 받아 들일 것이라고 말했다. 우리의 피-가치는 미리 결정된 유의 수준보다 낮기 때문에 귀무 가설을 거부하고 국가 간 와인의 평균 가격에 통계적으로 유의 한 차이가 있다고 말할 수 있습니다.
분산 분석은 옴니버스 테스트라는 것을 기억하십시오. 차이가 어디에 있는지 찾기 위해 우리는 한 번에 두 국가 간의 가설 테스트를 수행 할 것입니다.
자동 분산 분석
대부분의 생활에서와 마찬가지로 파이썬은 상태모델 라이브러리에서 분산 분석을 수행할 수 있는 직관적인 솔루션을 제공합니다. 아래 코드는 이 문서의 모든 계산을 수행하고 에프-통계 및 피-값으로 완성된 요약 테이블을 출력합니다.